
FBare-metal GPU instances ready in under 60 seconds. No queue, no waiting. Just compute when you need it.
Multi-GPU nodes interconnected at 900 GB/s. Train 70B+ parameter models without bandwidth bottlenecks.
Live GPU utilization, memory, power draw, and temperature. Full Prometheus metrics export included.
Attach high-speed NVMe volumes up to 25 TB. Data persists between runs, no re-download overhead.
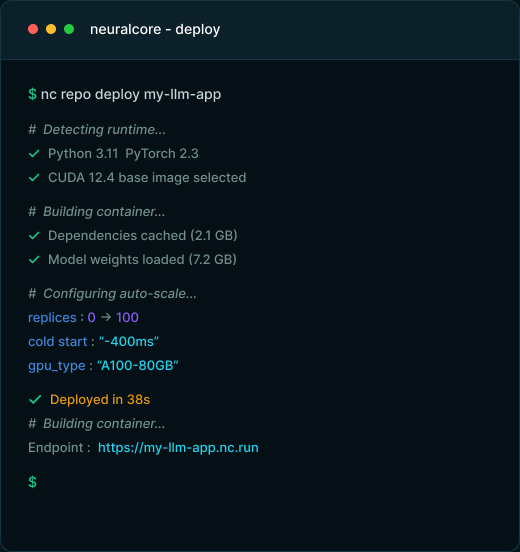
Push raw Python — we detect your stack, pin the right CUDA version, and build a production container automatically. No Dockerfile required.
Scale from zero to hundreds of GPU workers in seconds based on queue depth. Pay only for active inference time, not idle compute.
Connect your GitHub or GitLab repo. Every push to main triggers an automatic redeploy with zero-downtime blue/green rollout.
Your functions run across 8 global regions. Requests are auto-routed to the nearest warm replica for minimum latency.